MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning
,
,
,
,
,
,
,
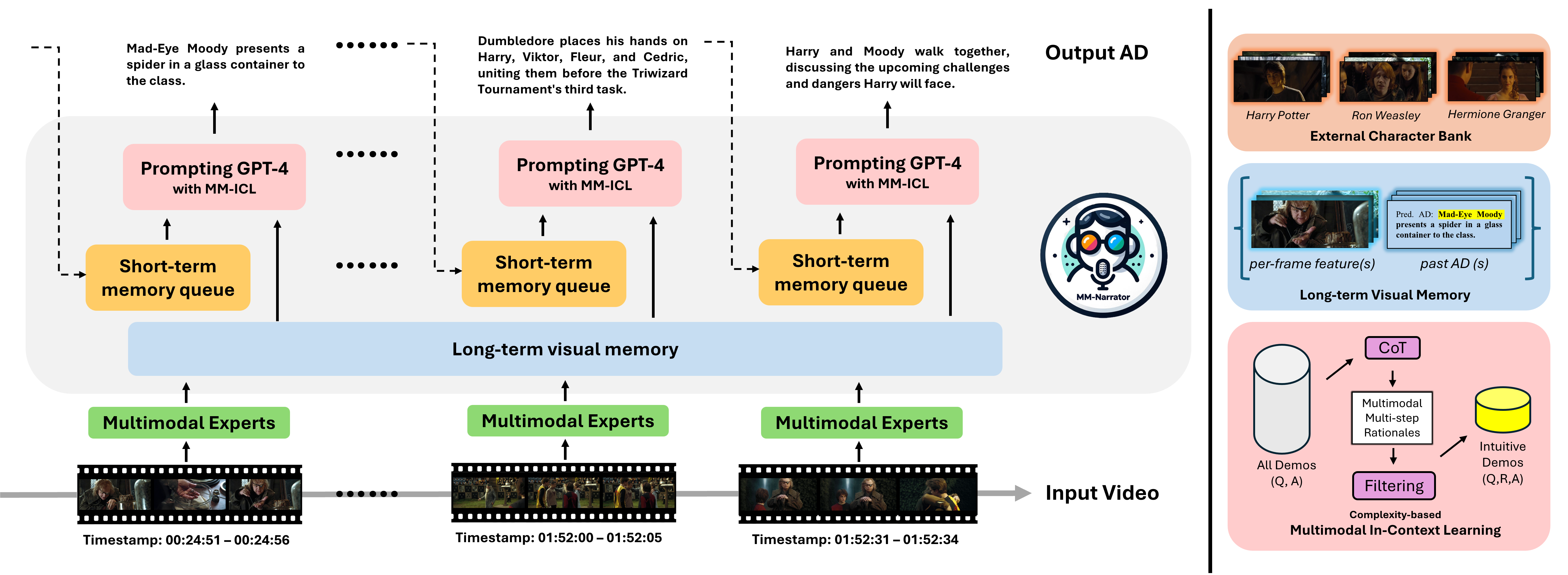
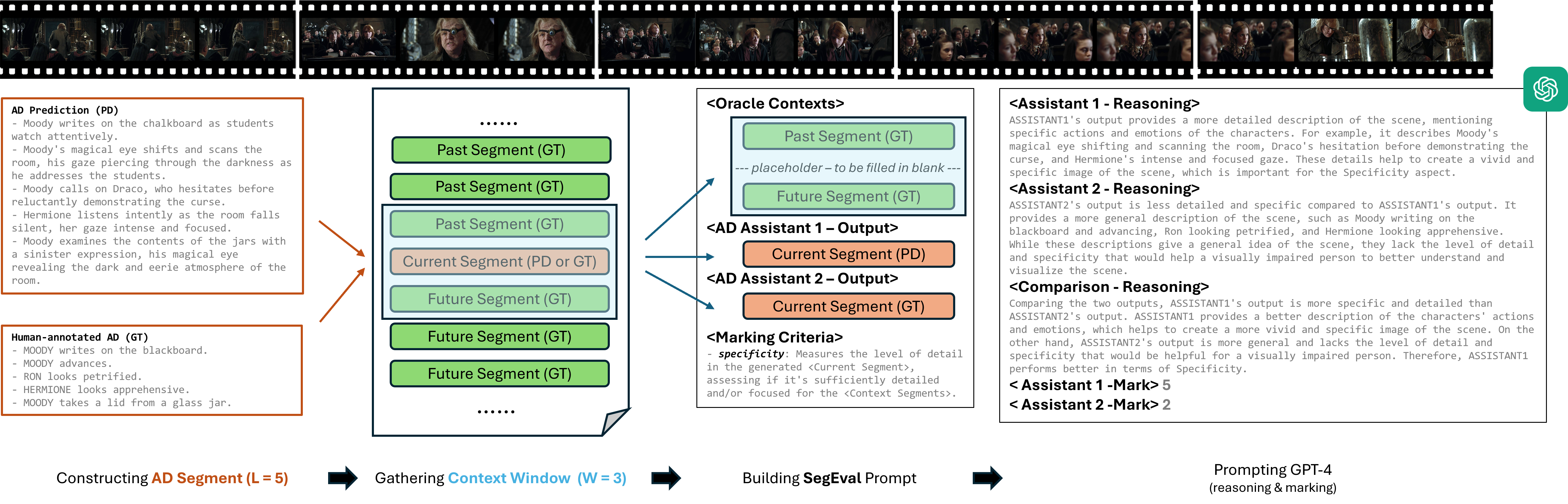
We present MM-Narrator, a novel system leveraging GPT-4 with multimodal in-context learning for the generation of audio descriptions (AD). Unlike previous methods that primarily focused on downstream fine-tuning with short video clips, MM-Narrator excels in generating precise audio descriptions for videos of extensive lengths, even beyond hours, in an autoregressive manner. This capability is made possible by the proposed memory-augmented generation process, which effectively utilizes both the short-term textual context and long-term visual memory through an efficient register-and-recall mechanism. These contextual memories compile pertinent past information, including storylines and character identities, ensuring an accurate tracking and depicting of story-coherent and character-centric audio descriptions. Maintaining the training-free design of MM-Narrator, we further propose a complexity-based demonstration selection strategy to largely enhance its multi-step reasoning capability via few-shot multimodal in-context learning (MM-ICL). Experimental results on MAD-eval dataset demonstrate that MM-Narrator consistently outperforms both the existing fine-tuning-based approaches and LLM-based approaches in most scenarios, as measured by standard evaluation metrics. Additionally, we introduce the first segment-based evaluator for recurrent text generation. Empowered by GPT-4, this evaluator comprehensively reasons and marks AD generation performance in various extendable dimensions.

We will release our data later, covering both AD generation and evaluation. For AD generation via MM-Narrator, we will release:
@article{zhang2023mmnarrator,
title= {MM-Narrator: Narrating Long-form Videos with Multimodal In-Context Learning},
author={Chaoyi Zhang, Kevin Lin, Zhengyuan Yang, Jianfeng Wang, Linjie Li, Chung-Ching Lin, Zicheng Liu, Lijuan Wang},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year={2024},
}
We are deeply grateful to OpenAI for providing access to their exceptional tool. We also extend heartfelt thanks to our Microsoft colleagues for their insights, with special acknowledgment to Faisal Ahmed, Ehsan Azarnasab, and Lin Liang for their constructive feedback.
This website is adapted from Nerfies, licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.